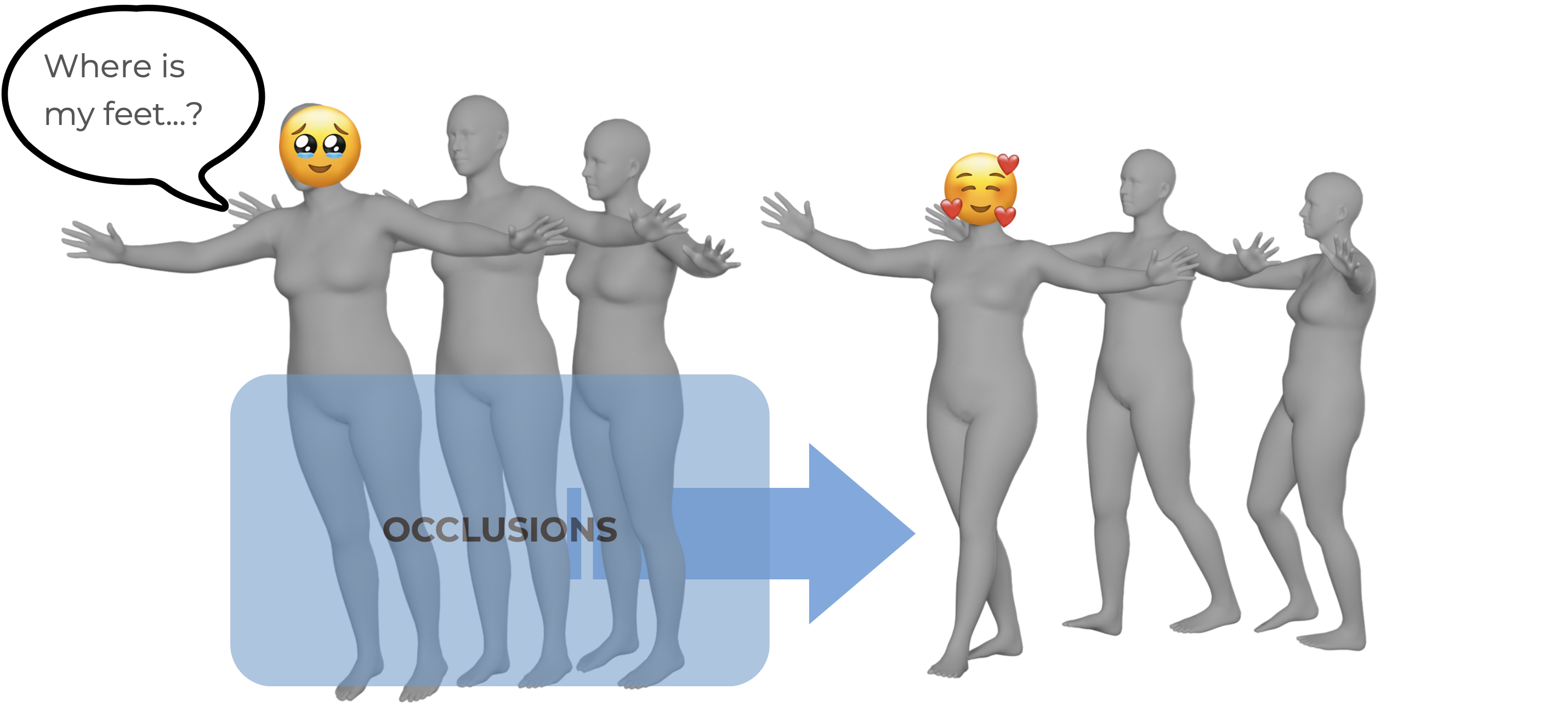
Motion capture often ends up… not great 🫠 — occlusions, missing joints, and jitter can really mess things up. Related works either rely on outdated neural networks (e.g. CVAE) that produce low-quality results or fail to prevent motion drift as the sequence is refined. We innovates a new pipeline that aims to refine corrupted motions directly from partial and messy inputs, restoring natural and coherent movement.
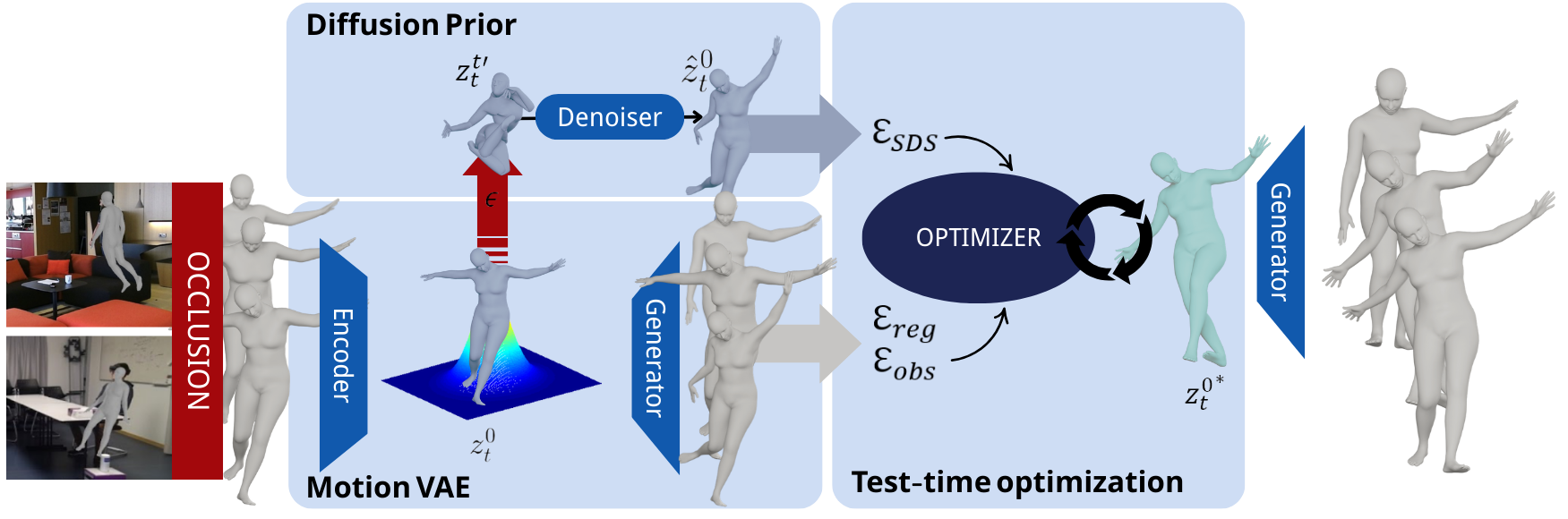
Our idea is simple: learn a powerful motion prior with diffusion models, and use it to denoise, restore, and imagine better motion! We formalize this task with an input of a masked or noisy motion sequence, and an output of a clean and coherent one. We embed both motion sequences with vectors
whose entries are root translation \( r \), root rotation \( \Phi \), joint rotation \( \Theta \), joint translation \( J \), and their derivatives.
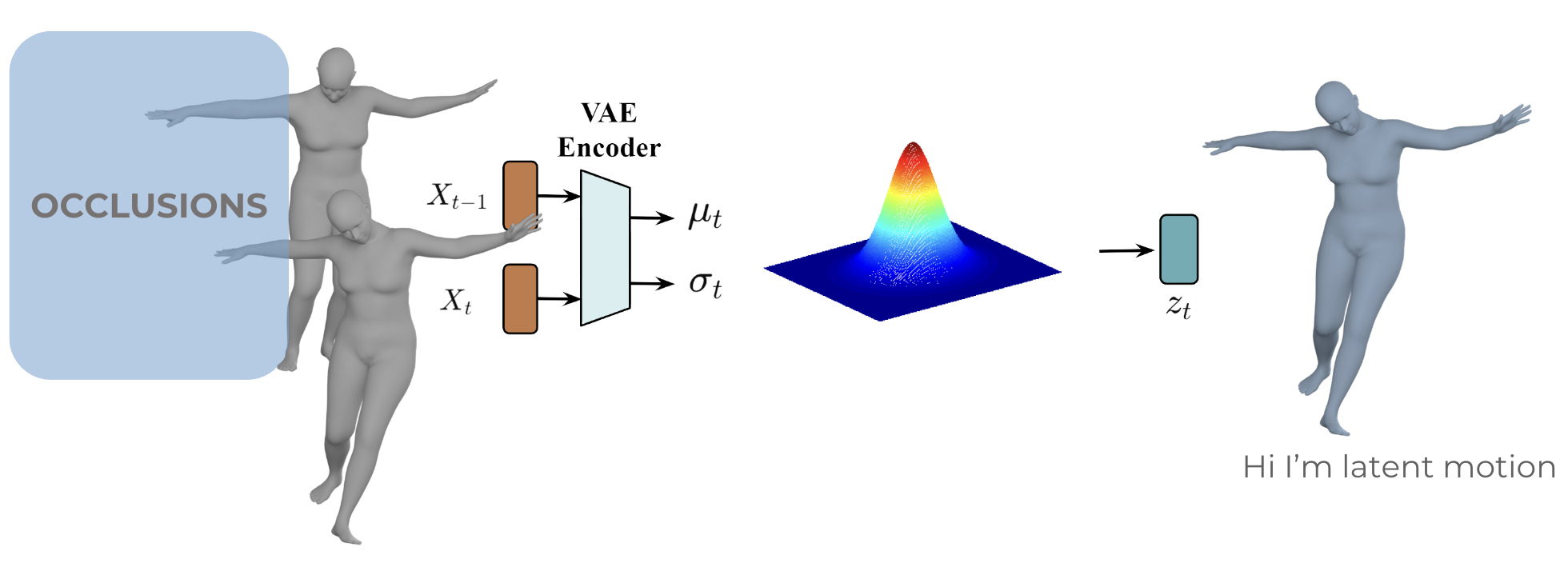
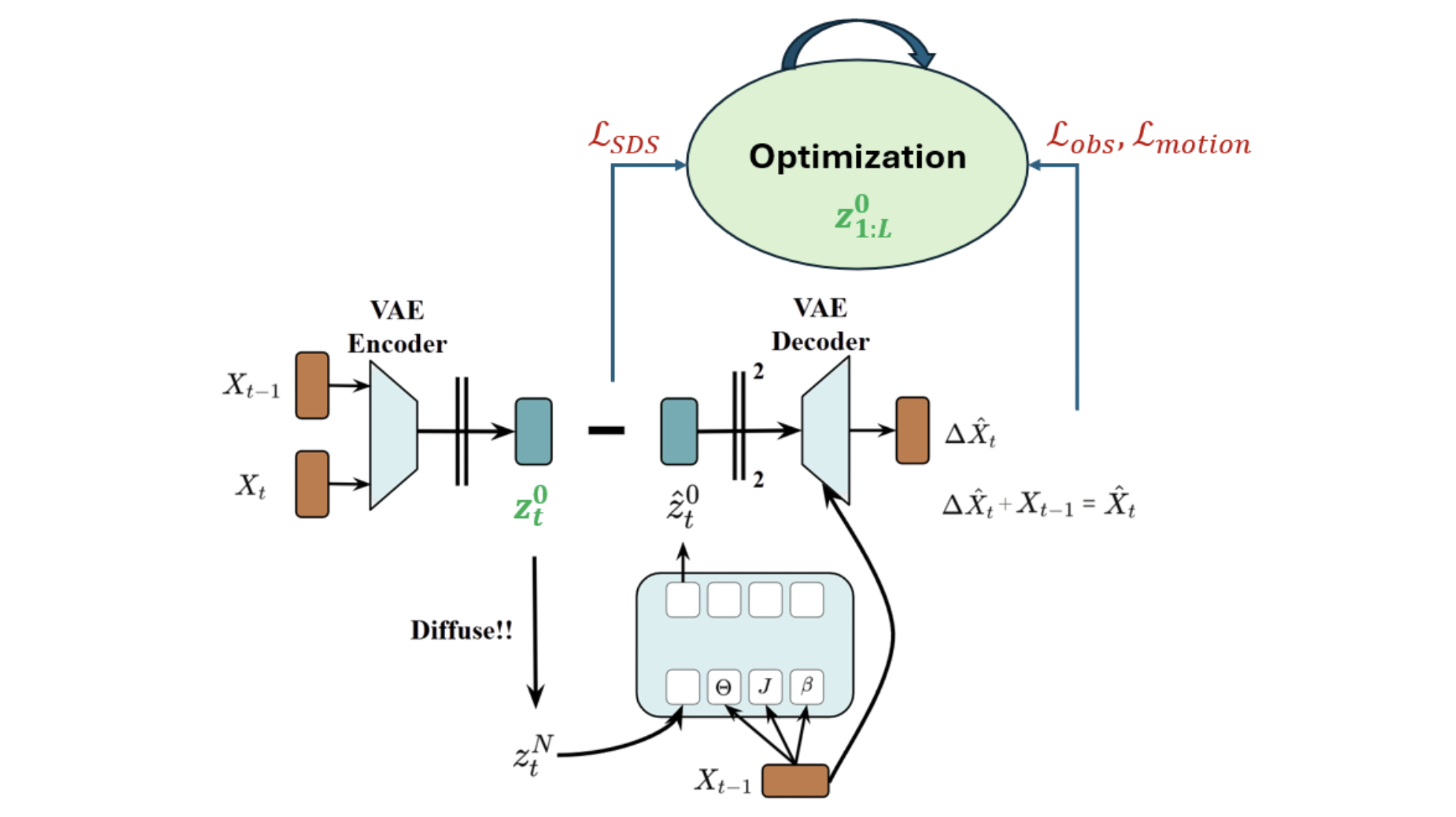
We hypothesize that operating motions in the latent space is preferable to the original motion space. Latent space is capable of generalizing complex motion dynamics and facilitate robust optimization during inference. We use a pre-trained VAE to encode the input motion \(X_t\) and the previous frame motion \(X_{t-1}\) into a latent vector \(z\). This latent space models the transition dynamics, capturing how motion evolves from \(X_{t-1}\) to \(X_t\).
A Transformer-based diffusion pipeline is the then used to predict the clean latent \(\hat{z}_t\), which aligns with the prior latent transition distribution conditioned on \(X_{t-1}\). Additionally, a decoder can be applied to the ground-truth latent representations to reconstruct the original motion sequences.
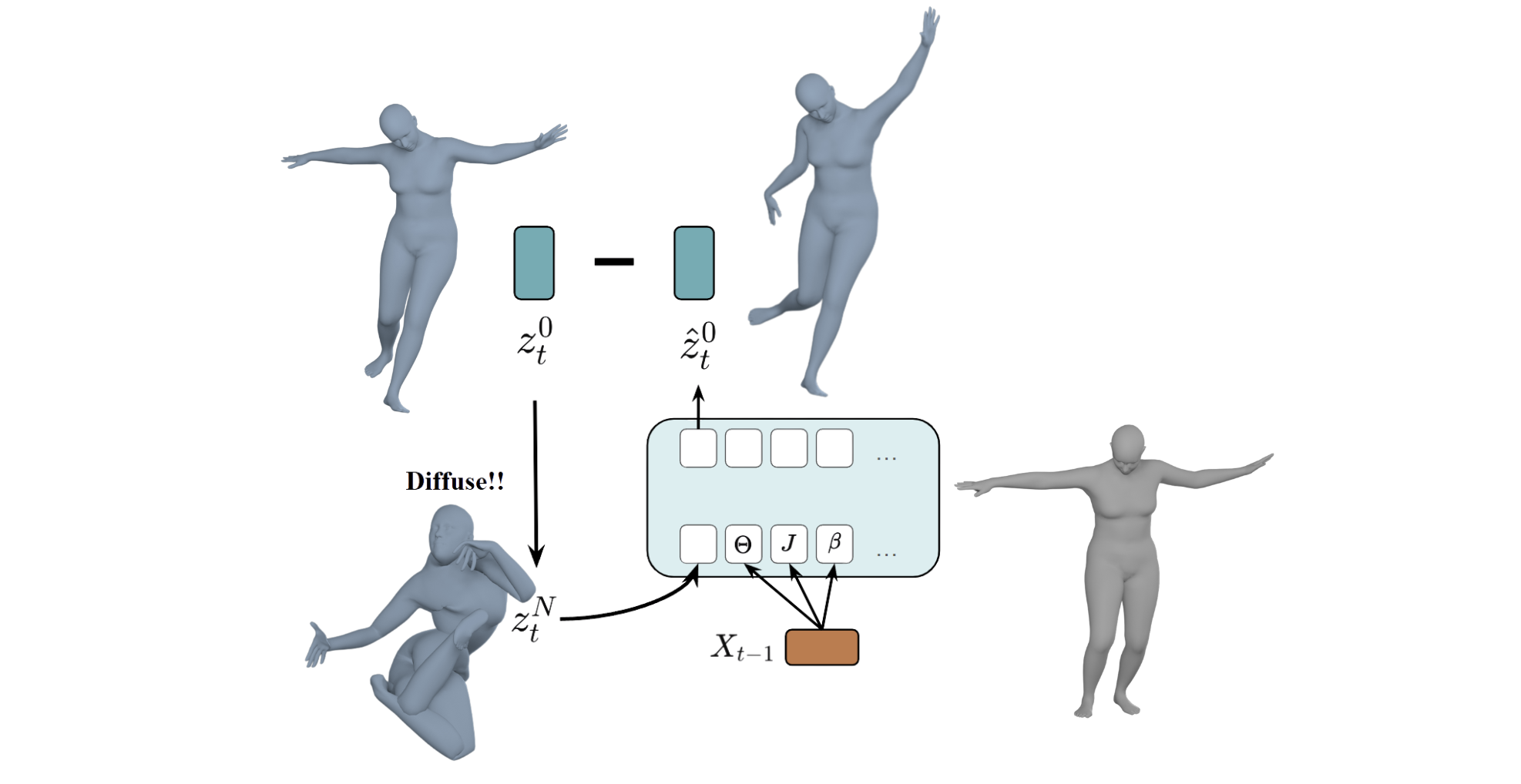
We calculate several meaningful losses at both the latent \(z\) and real motion \(X\) levels. These include a Score Diffusion Sampling loss in the latent space, as well as kinematic and observation constraints based on real motion data. The entire optimization process focuses on refining the latent sequence, ultimately producing clean, high-quality latent representations and decoded motion sequences.
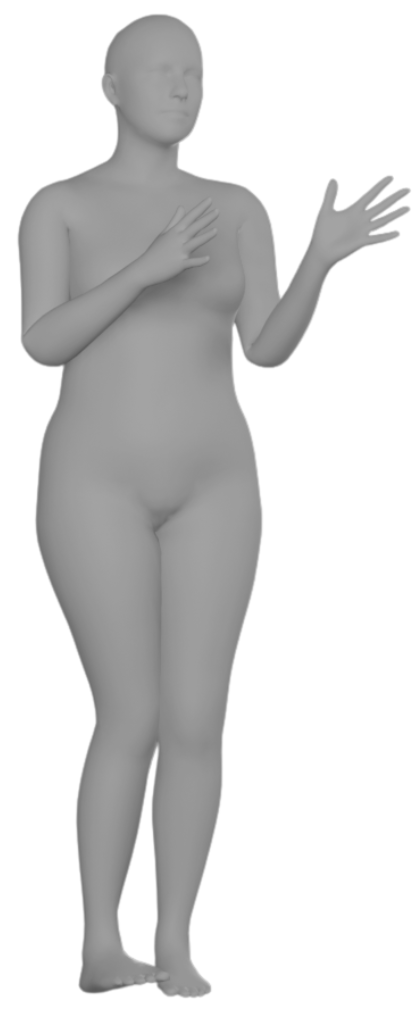
We conduct experiments by masking the lower-body joints of AMASS data, thereby removing all positional information for the lower body. And we report positional errors for all (All), occluded (Occ), and visible (Vis) observations separately, along with acceleration for smoothness evaluation and ground penetration for plausibility.