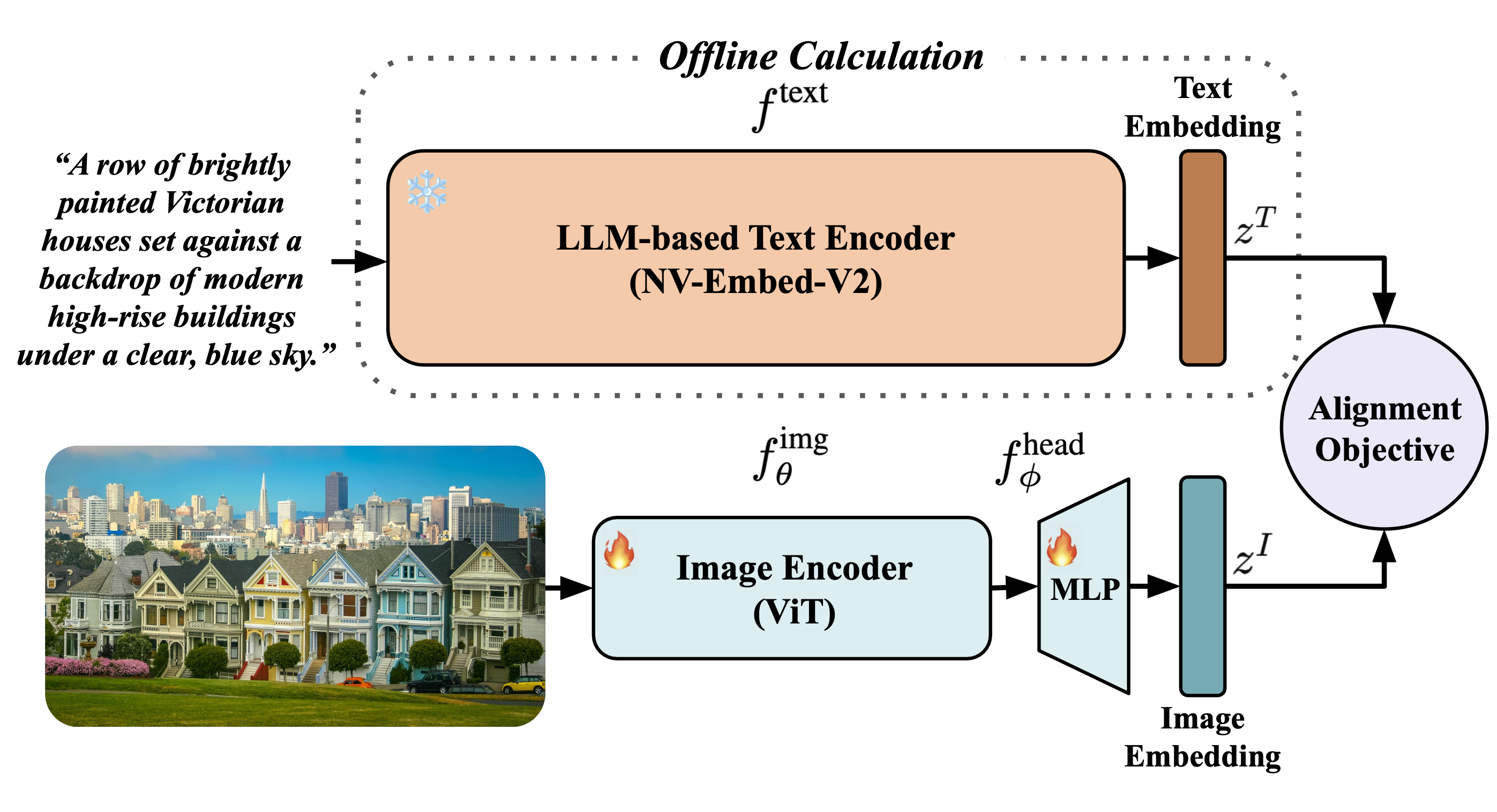
Currently, the most dominant approach to establishing language-image alignment is to pre-train (always from scratch) text and image encoders jointly through contrastive learning, such as CLIP and its variants.
In this work, we question whether such a costly joint training is necessary.
We investigate if a pre-trained fixed large language model (LLM) offers a good enough text encoder to guide visual representation learning. That is, we propose to learn Language-Image alignment with a Fixed Text encoder (LIFT) from an LLM by training only the image encoder.Somewhat surprisingly, through comprehensive benchmarking and ablation studies, we find that this much simplified framework LIFT is highly effective and it outperforms CLIP in most scenarios that involve

It is well known that CLIP lacks compositional understanding. Prior studies attribute this limitation to the fact that contrastive pre-training on general-purpose retrieval datasets incentivizes CLIP's encoders trained from scratch to adopt a shortcut strategy that suppresses (i.e. discards) features related to compositional information. We test the compositional understanding of LIFT and CLIP using SugarCrepe.
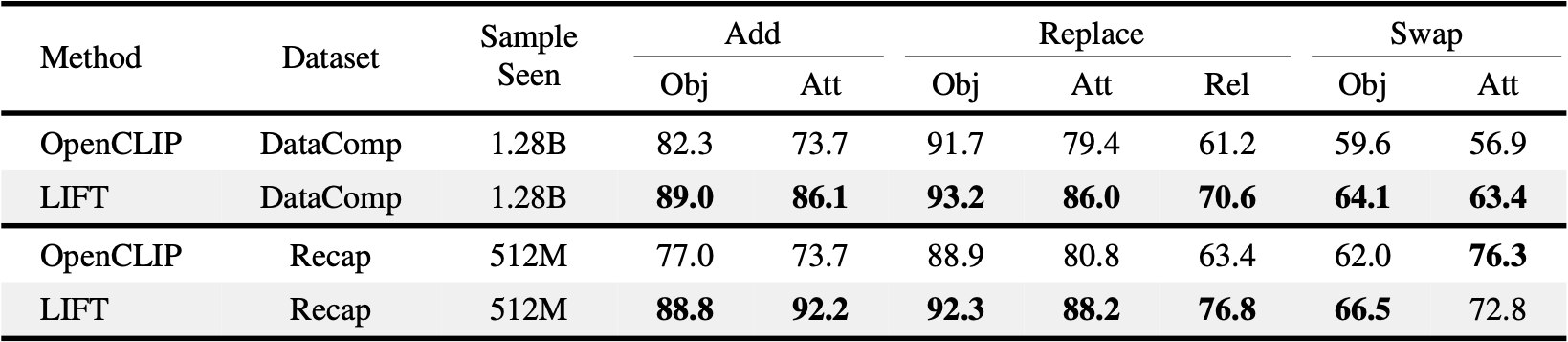
As shown in the table, when trained on the short captions from DataComp-1B, LIFT outperforms CLIP on all seven tasks with a 6.8% average accuracy gain; when trained on the long, synthetic captions from Recap-DataComp-1B, it leads on six tasks with a 7.9% gain. In both settings, LIFT achieves significant gains on add attribute, replace attribute, and replace relation tasks. These improvements are strong evidence that \(f^{\text{text}}\)'s auto-regressive training objective avoids the compositional oversight induced by contrastive learning and enables more accurate modeling of object–attribute associations and object–object relations.







LIFT's stronger compositional understanding also translates to improved performance on large multimodal models (LMMs) downstream tasks. We use LLaVA to train LMMs with either LIFT or CLIP as the vision tower, and observe that LIFT leads CLIP on five out of six tasks when both are trained on short captions and all six tasks when trained on long captions.
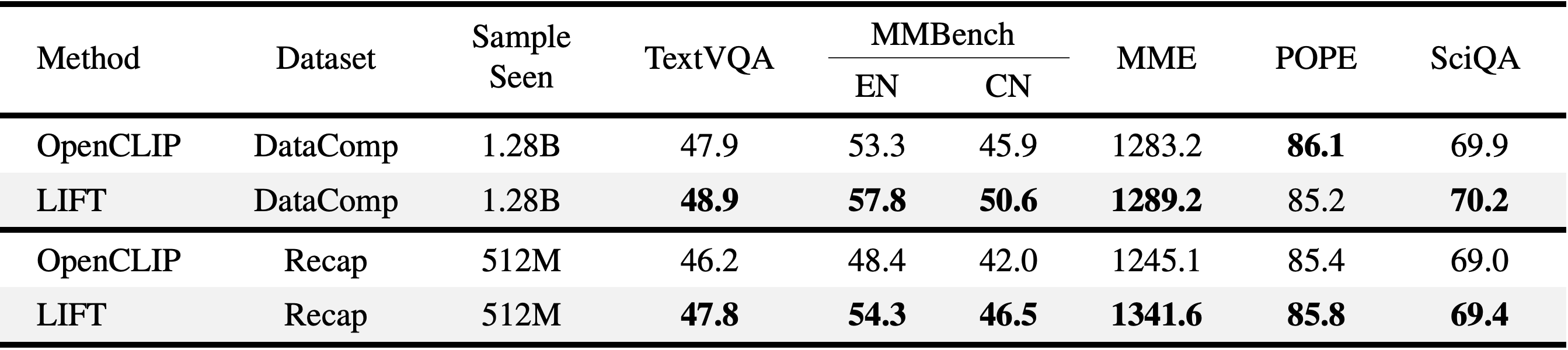
We find the gains mainly come from the subtasks requiring compositional understanding — such as MMBench's fine-grained perception (single-instance) and relational reasoning. The former subtask involves object localization and attribute recognition, while the latter includes identifying physical relations, all largely benefiting from LIFT's accurate encoding of compositional information.






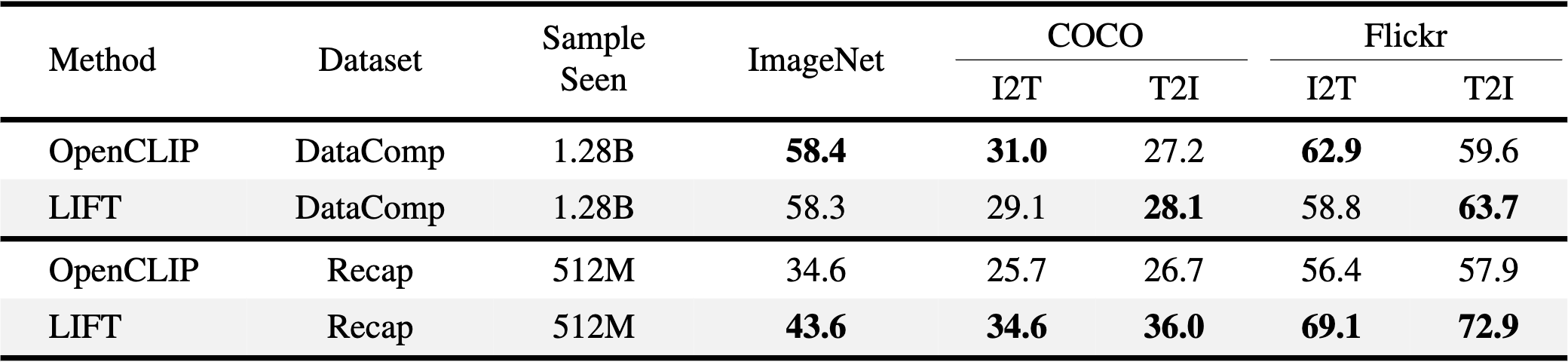
Recent studies show that CLIP yields suboptimal zero-shot performance when trained on full-length long captions (usually synthesized by VLMs), for its text encoder overemphasizes the syntactic similarity introduced by caption generators and fail to attend to semantically meaningful content. Here are three straightforward examples. We observe that CLIP's text encoder tends to assign higher scores to syntactically similar but semantically different caption pairs.

In contrast, LIFT employs the LLM-based text encoder pre-trained on large-scale data, resulting in an embedding space more robust to such syntactic homogeneity and better at extracting semantically meaningful features to distinguish captions. As shown in the table, when trained on short, web-scraped captions, CLIP has a slight edge over LIFT on ImageNet-1K zero-shot classification and two image-to-text retrieval tasks. However, all of these advantages are overtaken by LIFT with an average accuracy gain of 11.0% when both are trained on long, synthetic captions.
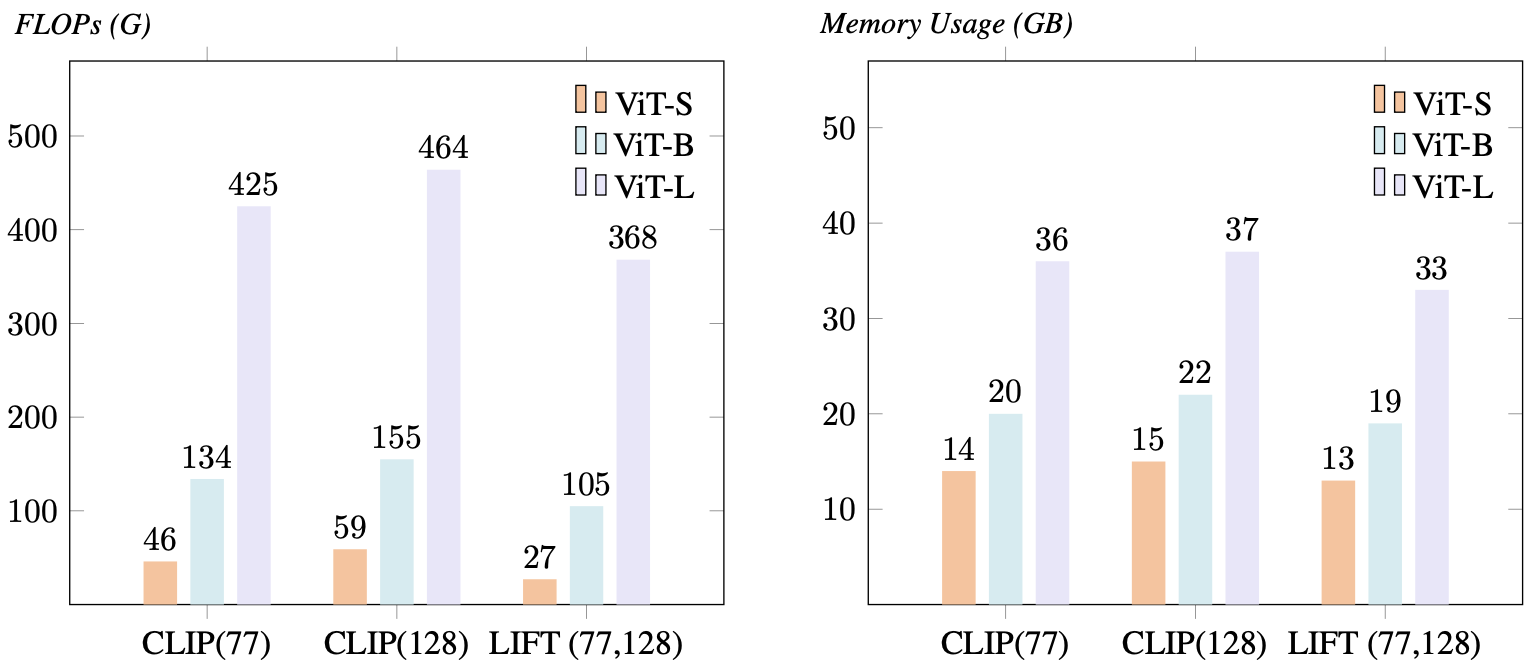
Since we don't optimize \(f^{\text{text}}\), the entire text embedding process can be performed offline. Given average per-batch max caption token length \(n\), the FLOPs and memory footprint of CLIP scale with \(\mathcal{O}(n^2)\) complexity, whereas LIFT achieves \(\mathcal{O}(1)\) amortized complexity. We also quantitatively benchmark CLIP and LIFT on both short (\(n=77\)) and long (\(n=128\)) captions. On average, LIFT reduces FLOPs by 25.5% for short captions and 35.7% for long ones, while lowering memory usage by 6.8% and 12.6%.
If you find our work inspiring, please consider giving a citation!
@misc{yang2025languageimagealignmentfixedtext,
title={Language-Image Alignment with Fixed Text Encoders},
author={Jingfeng Yang and Ziyang Wu and Yue Zhao and Yi Ma},
year={2025},
eprint={2506.04209},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.04209},
}